













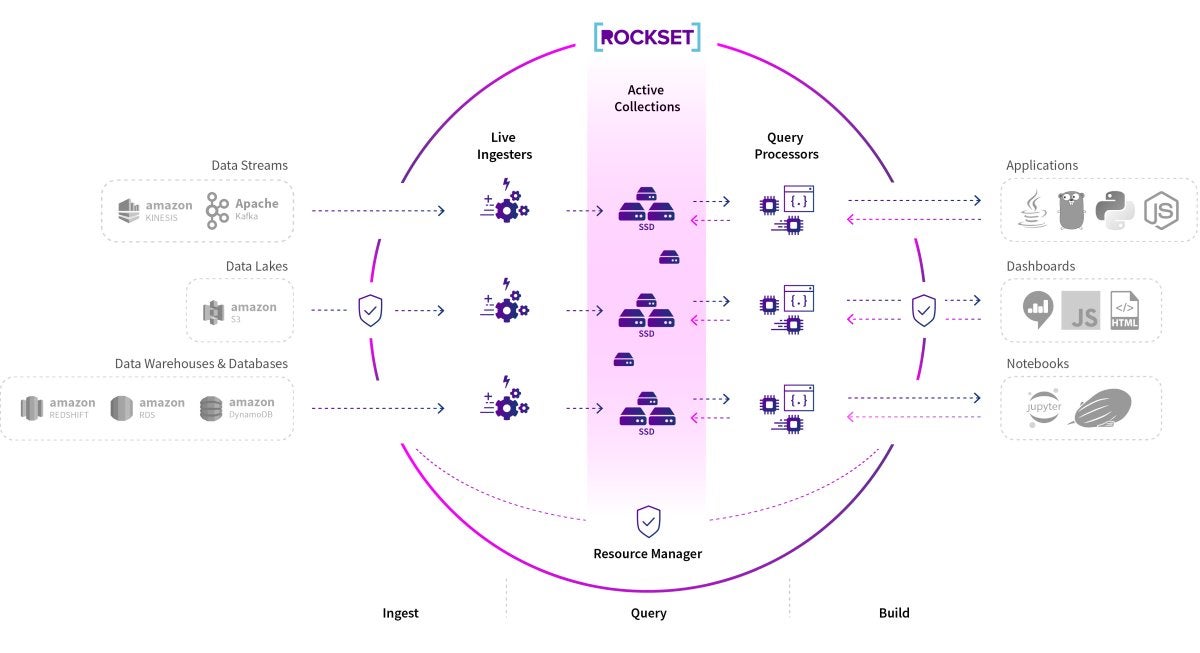
Main Highlights
- Rockset is dedicated to delivering real-time analytics to the stack so that businesses may utilize all of the information in event streams as it occurs.
- It has adjusted to manage the never-ending stream of bits that must be monitored and comprehended in order to ensure that modern, interaction-heavy websites function properly.
- Rockset can add indexing to the mix, albeit at the expense of skipping certain transaction processing.
- The ultimate result is extremely fast query performance and extremely low data latency.
Wasn’t it only a few years ago when a terabyte was considered a massive dataset? Now that every random internet of things device is “phoning home” a few hundred bytes at a time and every website wants to track what we do, terabytes don’t appear to be the proper unit any longer. The size of log files is increasing, and the only approach to enhance speed is to examine these never-ending recordings of every occurrence.
Rockset is one firm that is addressing this issue. It is dedicated to delivering real-time analytics to the stack so that businesses may utilize all of the information in event streams as it occurs. RocksDB, an open-source key-value database designed for low latency ingestion, serves as the foundation for the company’s service.
Rockset has adjusted it to manage the never-ending stream of bits that must be monitored and comprehended in order to ensure that modern, interaction-heavy websites function properly.
In a recent interview, Venkat Venkataramani, CEO of Rockset, discussed the technological hurdles involved in developing this solution. His perspective on data was shaped primarily by his technical leadership responsibilities at Facebook, where a wide range of data management breakthroughs happened.
According to Venkat Venkataramani, they are a database designed for real-time analytics on the cloud. When databases first became popular in the 1980s, there was just one type of database. It was a relational database used just for transaction processing.
After a period, around 20 years later, firms had accumulated enough data to warrant more advanced analytics to help them operate their operations more efficiently. As a result, data warehouses and data lakes were created. Now fast-forward another 20 years. Every company generates more data each year than Google had to index in 2000. Every company now has a massive amount of data, and they want real-time insights to develop better products.
Their customers want engaging real-time analytics. They require real-time iteration of business activities. And there, in my opinion, is where we should be concentrating our efforts. We refer to ourselves as a real-time analytics database or a real-time indexing database, and we are essentially a database created from the ground up to support real-time analytics in the cloud.

What is the distinction between standard transactional processing and real-time analytics or indexing databases?
“Transaction processing systems are typically quick, but they don’t [great at] sophisticated analytical queries,” Venkataramani adds. “They carry out basic tasks. They just generate a large number of records. I can make changes to the records. I may use it as my business’s record-keeping system. They’re fast, but they’re not really designed for computational scalability, are they? They are both for dependability. You know what I mean: don’t lose my info. This is my sole source of truth and my sole record-keeping method. It provides point-in-time recovery as well as transactional consistency.”
However, if they all require transactional consistency, transactional databases can only run a single node transaction database at a rate of around 100 writes per second. However, we’re talking about data torrents that generate millions of events each second. They’re not even in the game.
You then proceed to warehouses. They provide scalability, but they are excessively sluggish. Data entry into the system is too sluggish. It’s as though you’re living in the past. They are frequently hours, if not days, behind.
The warehouses and lakes provide scale, but not the speed that you might anticipate from a record system. Real-time databases, on the other hand, need both. The data never stops arriving, and it will come in floods. It will be arriving at a rate of millions of occurrences each second. That is the goal here. That is the ultimate objective. This is what the market needs. Speed, size, and simplicity are all important considerations.
Rockset can add indexing to the mix, albeit at the expense of skipping certain transaction processing. Rockset will provide the same performance as an old database but will forgo transactions because you will be executing real-time writes anyhow. We can scale since you don’t require transactions. Rockset’s speed, scalability, and ease of use are due to the combination of the converged index and the distributed SQL engine.
Another essential aspect of real-time analytics is the speed with which queries are executed. It is significant in terms of data latency, such as how soon data enters the system for query processing. But, more importantly, query processing must be quick.
Assume you’re able to construct a system that can collect data in real-time, but every time you ask a question, it takes 40 minutes for the answer to get back. It’s pointless. My data ingestion is quick, however, my queries are sluggish. It doesn’t matter because I’m still unable to gain real-time visibility into it. As a result, indexing is practically a means to an end.
The ultimate result is extremely fast query performance and extremely low data latency. So the true aim of real-time analytics is to do quick queries on fresh data. It is hardly real-time analytics if all you have are quick searches on outdated data.
Lucene v/s Elasticsearch v/s Rockset
The technology in Lucene is rather impressive considering when it was built and how far it has progressed. However, it was not designed for real-time analytics. The main distinction between Elastic and RocksDB is that Rockset offers full-featured SQL, including JOINs, GROUP BY, ORDER BY, window functions, and everything else you’d expect from a SQL database. This is something that Rockset is capable of. Elasticsearch is unable to.
When you can’t JOIN datasets at query time, you’re throwing a lot of operational complexity at the operator. As a result, Elasticsearch is mostly used for log analytics rather than business analytics. One significant advantage of log analytics is that JOINs are not required. You have a large number of logs to sift through; there are no JOINs.
Everything in business data is a JOIN with this or a JOIN with that. If you can’t JOIN datasets at query time, you’re forced to denormalize data at ingestion time, which is inconvenient from an operational standpoint. Data consistency is difficult to accomplish. It also incurs a significant amount of storage and computation overhead. So Lucene and Elasticsearch share certain concepts with Rockset, such as the usage of indexes for efficient data retrieval. Rockset, on the other hand, has created its real-time indexing engine in the cloud from the ground up, employing innovative algorithms. The code is written entirely in C++.
It employs convergent indexes, which provide both the functionality of a database index and the functionality of an inverted search index in the same data structure. Lucene provides half of what a converged index would provide. The remaining half will be provided by a data warehouse or columnar database. Converged indexes are an extremely efficient technique to create both.
A converged index is a general-purpose index that combines the benefits of both search and columnar indexes. Data warehouses are basic columnar formats. They are excellent for batch analytics. However, when it comes to real-time applications, you must be spinning compute and storage 24 hours a day, seven days a week. When this occurs, you require a compute-optimized system rather than a storage-optimized system.
Rockset has been optimized for computing. Because we are indexing, we will be able to provide you with 100 times better query performance. We create a slew of indexes on your data, and the identical data set will take up more storage in RocksDB byte for byte — but you’ll benefit from tremendous computational performance.
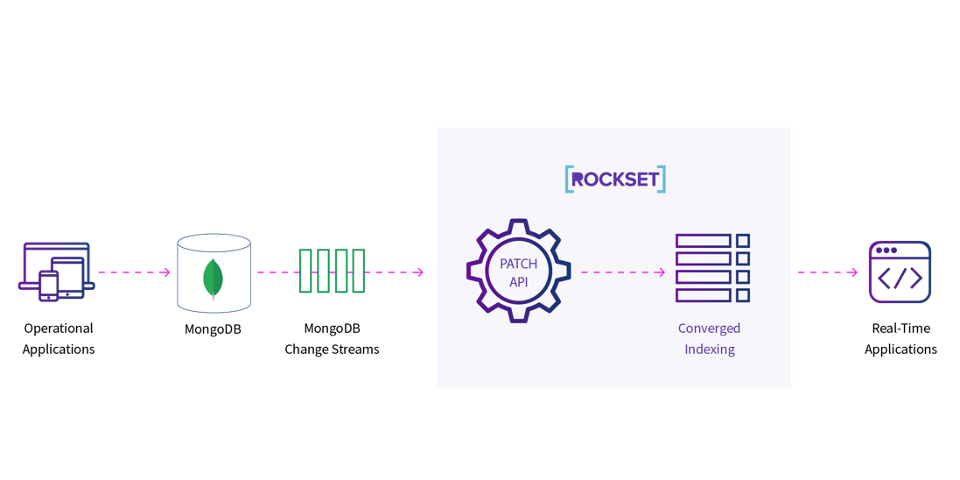
For real-time analytics, some data sources, such as Kafka or Kinesis, will contain data that does not necessarily reside elsewhere. It is arriving in big quantities. However, in order to do real-time analytics, these event streams must be linked to a system of record.
Some of your clickstream data may come from Kafka and be transformed into a quick SQL table in Rockset. However, it contains user IDs, product IDs, and other information that must be combined with your device data, product data, user data, and other information from your system of record.
As a result, Rockset has real-time data connectors for transactional systems such as Amazon DynamoDB, MongoDB, MySQL, and PostgreSQL. You can continue to make modifications to your system of record, and those changes will be reflected in real-time in Rockset. So you now have two real-time tables in Rockset: one from Kafka and one from your transactional system. You may now connect to it and do analytics on it. That is the guarantee.
How does this benefit the non-technical staff?
Many people argue, “I don’t need real-time because my staff only looks at these reports once a week and my marketing team doesn’t at all.” You don’t need this right now since your present systems and procedures aren’t designed to handle real-time data.
Nobody needs to look at these reports once a week after you’ve gone real-time. You will be paged promptly if any abnormalities occur. You are not required to attend a weekly meeting. People that go real-time never go back.
The true value proposition of such real-time data is that it accelerates your company’s growth. Your company does not operate in weekly or monthly increments. Your company is always developing and adapting to market demands. There are windows of opportunity to correct something or take advantage of an opportunity, and you must respond to them in real-time.
This is frequently overlooked while discussing technology and databases. However, the benefit of real-time analytics is so great that people are just embracing it.





{kind=link}